Computación paralela


La computación paralela es una forma de cómputo en la que muchas instrucciones se ejecutan simultáneamente,[1] operando sobre el principio de que problemas grandes, a menudo se pueden dividir en unos más pequeños, que luego son resueltos simultáneamente (en paralelo). Hay varias formas diferentes de computación paralela: paralelismo a nivel de bit, paralelismo a nivel de instrucción, paralelismo de datos y paralelismo de tareas. El paralelismo se ha empleado durante muchos años, sobre todo en la computación de altas prestaciones, pero el interés en ella ha crecido últimamente debido a las limitaciones físicas que impiden el aumento de la frecuencia.[n. 1][2] Como el consumo de energía —y por consiguiente la generación de calor— de las computadoras constituye una preocupación en los últimos años,[n. 2][3] la computación en paralelo se ha convertido en el paradigma dominante en la arquitectura de computadores, principalmente en forma de procesadores multinúcleo.[n. 3][4]
Las computadoras paralelas pueden clasificarse según el nivel de paralelismo que admite su hardware: equipos con procesadores multinúcleo y multi-procesador que tienen múltiples elementos de procesamiento dentro de una sola máquina y los clústeres, MPPS y grids que utilizan varios equipos para trabajar en la misma tarea. Muchas veces, para acelerar tareas específicas, se utilizan arquitecturas especializadas de computación en paralelo junto a procesadores tradicionales.
Los programas informáticos paralelos son más difíciles de escribir que los secuenciales,[5] porque la concurrencia introduce nuevos tipos de errores de software, siendo las condiciones de carrera los más comunes. La comunicación y sincronización entre diferentes subtareas son algunos de los mayores obstáculos para obtener un buen rendimiento del programa paralelo.
La máxima aceleración posible de un programa como resultado de la paralelización se conoce como la ley de Amdahl.
Conceptos básicos
[editar]Tradicionalmente, los programas informáticos se han escrito para el cómputo en serie. Para resolver un problema, se construye un algoritmo y se implementa como un flujo en serie de instrucciones. Estas instrucciones se ejecutan en una unidad central de procesamiento en un ordenador. Sólo puede ejecutarse una instrucción a la vez y un tiempo después de que la instrucción ha terminado, se ejecuta la siguiente.[6]
La computación en paralelo, por el contrario, utiliza simultáneamente múltiples elementos de procesamiento para resolver un problema. Esto se logra mediante la división del problema en partes independientes de modo que cada elemento de procesamiento pueda ejecutar su parte del algoritmo de manera simultánea con los otros. Los elementos de procesamiento son diversos e incluyen recursos tales como una computadora con múltiples procesadores, varios ordenadores en red, hardware especializado, o cualquier combinación de los anteriores.[6]
El aumento de la frecuencia fue la razón dominante de las mejoras en el rendimiento de las computadoras desde mediados de 1980 hasta el año 2004. El tiempo de ejecución de un programa es igual al número de instrucciones multiplicado por el tiempo promedio por instrucción. Manteniendo todo lo demás constante, el aumento de la frecuencia de reloj reduce el tiempo medio que tarda en ejecutarse una instrucción, por tanto un aumento en la frecuencia reduce el tiempo de ejecución de los programas de cómputo.[7]
Sin embargo, el consumo de energía de un chip está dada por la ecuación P = C × V2 × F, donde P es la potencia, C es el cambio de capacitancia por ciclo de reloj —proporcional al número de transistores cuyas entradas cambian—, V es la tensión, y F es la frecuencia del procesador (ciclos por segundo).[8] Un aumento en la frecuencia aumenta la cantidad de energía utilizada en un procesador. El aumento del consumo de energía del procesador llevó a Intel en mayo del 2004 a la cancelación de sus procesadores Tejas y Jayhawk, este hecho generalmente se cita como el fin del escalado de frecuencia como el paradigma dominante de arquitectura de computadores.[9]
La ley de Moore es la observación empírica de que la densidad de transistores en un microprocesador se duplica cada 18 a 24 meses.[10] A pesar de los problemas de consumo de energía, y las repetidas predicciones de su fin, la ley de Moore sigue vigente. Con el fin del aumento de la frecuencia, estos transistores adicionales —que ya no se utilizan para el aumento de la frecuencia— se pueden utilizar para añadir hardware adicional que permita la computación paralela.
Ley de Amdahl y ley de Gustafson
[editar]
Idealmente, la aceleración a partir de la paralelización es lineal, doblar el número de elementos de procesamiento debe reducir a la mitad el tiempo de ejecución y doblarlo por segunda vez debe nuevamente reducir el tiempo a la mitad. Sin embargo, muy pocos algoritmos paralelos logran una aceleración óptima. La mayoría tienen una aceleración casi lineal para un pequeño número de elementos de procesamiento, y pasa a ser constante para un gran número de elementos de procesamiento.
La aceleración potencial de un algoritmo en una plataforma de cómputo en paralelo está dada por la ley de Amdahl, formulada originalmente por Gene Amdahl en la década de 1960.[11] Esta señala que una pequeña porción del programa que no pueda paralelizarse va a limitar la aceleración que se logra con la paralelización. Los programas que resuelven problemas matemáticos o ingenieriles típicamente consisten en varias partes paralelizables y varias no paralelizables (secuenciales). Si es la fracción de tiempo que un programa gasta en partes no paralelizables, luego
es la máxima aceleración que se puede alcanzar con la paralelización del programa. Si la parte secuencial del programa abarca el 10% del tiempo de ejecución, se puede obtener no más de 10× de aceleración, independientemente de cuántos procesadores se añadan. Esto pone un límite superior a la utilidad de añadir más unidades de ejecución paralelas. «Cuando una tarea no puede dividirse debido a las limitaciones secuenciales, la aplicación de un mayor esfuerzo no tiene efecto sobre la programación. La gestación de un niño toma nueve meses, no importa cuántas mujeres se le asigne».[12]
La ley de Gustafson es otra ley en computación que está en estrecha relación con la ley de Amdahl.[13] Señala que el aumento de velocidad con procesadores es

Ambas leyes asumen que el tiempo de funcionamiento de la parte secuencial del programa es independiente del número de procesadores. La ley de Amdahl supone que todo el problema es de tamaño fijo, por lo que la cantidad total de trabajo que se hará en paralelo también es independiente del número de procesadores, mientras que la ley de Gustafson supone que la cantidad total de trabajo que se hará en paralelo varía linealmente con el número de procesadores.
Dependencias
[editar]Entender la dependencia de datos es fundamental en la implementación de algoritmos paralelos. Ningún programa puede ejecutar más rápidamente que la cadena más larga de cálculos dependientes (conocida como la ruta crítica), ya que los cálculos que dependen de cálculos previos en la cadena deben ejecutarse en orden. Sin embargo, la mayoría de los algoritmos no consisten sólo de una larga cadena de cálculos dependientes; generalmente hay oportunidades para ejecutar cálculos independientes en paralelo.
Sea Pi y Pj dos segmentos del programa. Las condiciones de Bernstein[14] describen cuando los dos segmentos son independientes y pueden ejecutarse en paralelo. Para Pi, sean Ii todas las variables de entrada y Oi las variables de salida, y del mismo modo para Pj. P i y Pj son independientes si satisfacen
Una violación de la primera condición introduce una dependencia de flujo, correspondiente al primer segmento que produce un resultado utilizado por el segundo segmento. La segunda condición representa una anti-dependencia, cuando el segundo segmento (Pj) produce una variable que necesita el primer segmento (Pi). La tercera y última condición representa una dependencia de salida: Cuando dos segmentos escriben en el mismo lugar, el resultado viene del último segmento ejecutado.[15]
Considere las siguientes funciones, que demuestran varios tipos de dependencias:
1: función Dep(a, b) 2: c: = a · b 3: d: = 3 · c 4: fin función
La operación 3 en Dep(a, b) no puede ejecutarse antes de —o incluso en paralelo con— la operación 2, ya que en la operación 3 se utiliza un resultado de la operación 2. Esto viola la condición 1, y por tanto introduce una dependencia de flujo.
1: función NoDep (a, b) 2: c: = a · b 3: d: b = 3 · 4: e: = a + b 5: fin función
En este ejemplo, no existen dependencias entre las instrucciones, por lo que todos ellos se pueden ejecutar en paralelo.
Las condiciones de Bernstein no permiten que la memoria se comparta entre los diferentes procesos. Por esto son necesarios algunos medios que impongan un ordenamiento entre los accesos tales como semáforos, barreras o algún otro método de sincronización.
Condiciones de carrera, exclusión mutua, sincronización, y desaceleración paralela
[editar]Las subtareas en un programa paralelo a menudo son llamadas hilos. Algunas arquitecturas de computación paralela utilizan versiones más pequeñas y ligeras de hilos conocidas como hebras, mientras que otros utilizan versiones más grandes conocidos como procesos. Sin embargo, «hilos» es generalmente aceptado como un término genérico para las subtareas. Los hilos a menudo tendrán que actualizar algunas variables que se comparten entre ellos. Las instrucciones entre los dos programas pueden entrelazarse en cualquier orden. Por ejemplo, considere el siguiente programa:
| Hilo A | Hilo B |
| 1A: Lee variable V | 1B: Lee variable V |
| 2A: Añadir 1 a la variable V | 2B: Añadir 1 a la variable V |
| 3A: Escribir en la variable V | 3B: Escribir en la variable V |
Si la instrucción 1B se ejecuta entre 1A y 3A, o si la instrucción 1A se ejecuta entre 1B y 3B, el programa va a producir datos incorrectos. Esto se conoce como una condición de carrera. El programador debe utilizar un bloqueo (lock) para proporcionar exclusión mutua. Un bloqueo es una construcción del lenguaje de programación que permite a un hilo de tomar el control de una variable y evitar que otros hilos la lean o escriban, hasta que la variable esté desbloqueado. El hilo que mantiene el bloqueo es libre de ejecutar su sección crítica —la sección de un programa que requiere acceso exclusivo a alguna variable—, y desbloquear los datos cuando termine. Por lo tanto, para garantizar la correcta ejecución del programa, el programa anterior se puede reescribir usando bloqueos:
| Hilo A | Hilo B |
| 1A: Bloquear variable V | 1B: Bloquear variable V |
| 2A: Lee variable V | 2B: Lee variable V |
| 3A: Añadir 1 a la variable V | 3B: Añadir 1 a la variable V |
| 4A: Escribir en la variable V | 4B: Escribir en la variable V |
| 5A: Desbloquear variable V | 5B: Desbloquear variable V |
Un hilo bloqueará con éxito la variable V, mientras que el otro hilo no podrá continuar hasta que V se desbloquee. Esto garantiza la correcta ejecución del programa. Si bien los bloqueos son necesarios para asegurar la ejecución correcta del programa, pueden ralentizar en gran medida un programa.
Bloquear múltiples variables utilizando cerraduras no atómicas introduce la posibilidad de que el programa alcance un bloqueo mutuo (deadlock). Un bloqueo atómico bloquea múltiples variables a la vez, si no puede bloquearlas todas, no se bloquea ninguna de ellas. Si hay dos hilos y cada uno necesita bloquear las mismas dos variables utilizando cerraduras no atómicas, es posible que un hilo bloquee uno de ellas y el otro bloquee la segunda variable. En tal caso se produce un bloqueo mutuo donde ningún hilo puede completar la ejecución.
Muchos programas paralelos requieren que sus subtareas actúen en sincronía. Esto requiere el uso de una barrera. Las barreras se implementan normalmente mediante un bloqueo. Una clase de algoritmos, conocida como algoritmos libres de bloqueo y libres de espera, evitan el uso de bloqueos y barreras. Sin embargo, este enfoque es generalmente difícil de implementar y requiere estructuras de datos correctamente diseñadas.
No todas las paralelizaciones conllevan una aceleración. Por lo general, mientras una tarea se divida en cada vez más hilos, estos hilos pasan una porción cada vez mayor de su tiempo comunicándose entre sí. Finalmente, la sobrecarga de comunicación domina el tiempo empleado para resolver el problema, y la paralelización adicional —dividir la carga de trabajo entre incluso más hilos— aumenta la cantidad de tiempo requerido para terminar. Esto se conoce como desaceleración paralela.
Paralelismo de grano fino, grano grueso y paralelismo vergonzoso
[editar]Las aplicaciones a menudo se clasifican según la frecuencia con que sus subtareas se sincronizan o comunican entre sí. Una aplicación muestra un paralelismo de grano fino si sus subtareas deben comunicase muchas veces por segundo, se considera paralelismo de grano grueso si no se comunican muchas veces por segundo, y es vergonzosamente paralelo si nunca o casi nunca se tienen que comunicar. Aplicaciones vergonzosamente paralelas son consideradas las más fáciles de paralelizar.
Modelos de consistencia
[editar]
Los lenguajes de programación en paralelo y computadoras paralelas deben tener un modelo de consistencia de datos —también conocido como un modelo de memoria—. El modelo de consistencia define reglas para las operaciones en la memoria del ordenador y cómo se producen los resultados.
Uno de los primeros modelos de consistencia fue el modelo de consistencia secuencial de Leslie Lamport. La consistencia secuencial es la propiedad de un programa en la que su ejecución en paralelo produce los mismos resultados que un programa secuencial. Específicamente, es un programa secuencial consistente si «... los resultados de una ejecución son los mismos que se obtienen si las operaciones de todos los procesadores son ejecutadas en un orden secuencial, y las operaciones de cada procesador individual aparecen en esta secuencia en el orden especificado por el programa».[16]
La memoria transaccional es un tipo de modelo de consistencia. La memoria transaccional toma prestado de la teoría de base de datos el concepto de transacciones atómicas y las aplica a los accesos a memoria.
Matemáticamente, estos modelos se pueden representar de varias maneras. Las Redes de Petri, que se introdujeron en 1962 como tesis doctoral de Carl Adam Petri, fueron un primer intento de codificar las reglas de los modelos de consistencia. Más tarde fueron creadas las arquitecturas de flujo de datos para implementar físicamente las ideas de la teoría del flujo de datos. A principios de la década de 1970, los cálculos de procesos tales como la Comunicación de Sistemas y Comunicación de Procesos Secuenciales se desarrollaron para permitir un razonamiento algebraico sobre sistemas compuestos por elementos que interactúan entre sí. Adiciones más recientes a la familia de cálculo de proceso, como el cálculo-π, han añadido la capacidad para razonar acerca de las topologías dinámicas. Lógicas tales como la TLA+ de Lamport, y modelos matemáticos se han desarrollado para describir el comportamiento de sistemas concurrentes.
Taxonomía de Flynn
[editar]Michael J. Flynn creó uno de los primeros sistemas de clasificación de computadoras, programas paralelos y secuenciales, ahora conocida como la taxonomía de Flynn. Flynn clasifica los programas y computadoras atendiendo a si están operando con uno o varios conjuntos de instrucciones y si esas instrucciones se utilizan en una o varias series de datos.
| Instrucción individual | Instrucción múltiple | |
| Datos individuales | SISD | MISD |
| Múltiples datos | SIMD | MIMD |
La clasificación instrucción-única-dato-único (SISD) es equivalente a un programa totalmente secuencial. La clasificación instrucción-única-datos-múltiples (SIMD) es análoga a hacer la misma operación varias veces sobre un conjunto de datos grande. Esto se hace comúnmente en aplicaciones de procesamiento de señales. Instrucciones-múltiples-dato-único (MISD) es una clasificación que rara vez se utiliza. A pesar de que se diseñaron arquitecturas de computadoras en esta categoría —como arreglos sistólicos—, muy pocas aplicaciones se materializaron. Los programas instrucciones-múltiples-datos-múltiples (MIMD) constituyen el tipo más común de programas paralelos.
Según David A. Patterson y John L. Hennessy, «Algunas máquinas son híbridos de estas categorías, por supuesto, este modelo clásico ha sobrevivido porque es simple, fácil de entender, y da una buena primera aproximación. Además, es, tal vez por su comprensibilidad, el esquema más utilizado.»[17]
Tipos de paralelismo
[editar]Paralelismo a nivel de bit
[editar]Desde el advenimiento de la integración a gran escala (VLSI) como tecnología de fabricación de chips de computadora en la década de 1970 hasta alrededor de 1986, la aceleración en la arquitectura de computadores se lograba en gran medida duplicando el tamaño de la palabra en la computadora, la cantidad de información que el procesador puede manejar por ciclo.[18] El aumento del tamaño de la palabra reduce el número de instrucciones que el procesador debe ejecutar para realizar una operación en variables cuyos tamaños son mayores que la longitud de la palabra. Por ejemplo, cuando un procesador de 8 bits debe sumar dos enteros de 16 bits, el procesador primero debe adicionar los 8 bits de orden inferior de cada número entero con la instrucción de adición, a continuación, añadir los 8 bits de orden superior utilizando la instrucción de adición con acarreo que tiene en cuenta el bit de acarreo de la adición de orden inferior, en este caso un procesador de 8 bits requiere dos instrucciones para completar una sola operación, en donde un procesador de 16 bits necesita una sola instrucción para poder completarla.
Históricamente, los microprocesadores de 4 bits fueron sustituidos por unos de 8 bits, luego de 16 bits y 32 bits, esta tendencia general llegó a su fin con la introducción de procesadores de 64 bits, lo que ha sido un estándar en la computación de propósito general durante la última década.
Paralelismo a nivel de instrucción
[editar]
Un programa de ordenador es, en esencia, una secuencia de instrucciones ejecutadas por un procesador. Estas instrucciones pueden reordenarse y combinarse en grupos que luego son ejecutadas en paralelo sin cambiar el resultado del programa. Esto se conoce como paralelismo a nivel de instrucción. Los avances en el paralelismo a nivel de instrucción dominaron la arquitectura de computadores desde mediados de 1980 hasta mediados de la década de 1990.[19]
Los procesadores modernos tienen ''pipeline'' de instrucciones de varias etapas. Cada etapa en el pipeline corresponde a una acción diferente que el procesador realiza en la instrucción correspondiente a la etapa; un procesador con un pipeline de N etapas puede tener hasta n instrucciones diferentes en diferentes etapas de finalización. El ejemplo canónico de un procesador segmentado es un procesador RISC, con cinco etapas: pedir instrucción, decodificar, ejecutar, acceso a la memoria y escritura. El procesador Pentium 4 tenía un pipeline de 35 etapas.[20]
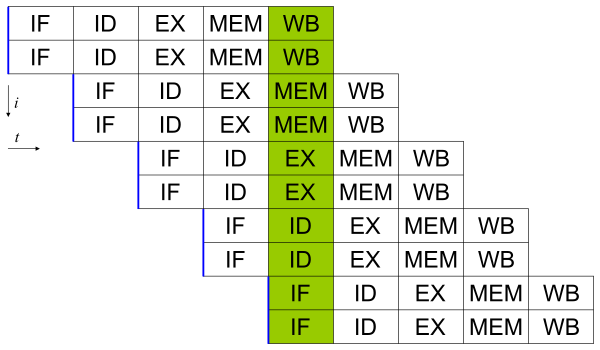
Además del paralelismo a nivel de instrucción del pipelining, algunos procesadores pueden ejecutar más de una instrucción a la vez. Estos son conocidos como procesadores superescalares. Las instrucciones pueden agruparse juntas sólo si no hay dependencia de datos entre ellas. El scoreboarding y el algoritmo de Tomasulo —que es similar a scoreboarding pero hace uso del renombre de registros— son dos de las técnicas más comunes para implementar la ejecución fuera de orden y la paralelización a nivel de instrucción.
Paralelismo de datos
[editar]El paralelismo de datos es el paralelismo inherente en programas con ciclos, que se centra en la distribución de los datos entre los diferentes nodos computacionales que deben tratarse en paralelo. «La paralelización de ciclos conduce a menudo a secuencias similares de operaciones —no necesariamente idénticas— o funciones que se realizan en los elementos de una gran estructura de datos».[21] Muchas de las aplicaciones científicas y de ingeniería muestran paralelismo de datos.
Una dependencia de terminación de ciclo es la dependencia de una iteración de un ciclo en la salida de una o más iteraciones anteriores. Las dependencias de terminación de ciclo evitan la paralelización de ciclos. Por ejemplo, considere el siguiente pseudocódigo que calcula los primeros números de Fibonacci:
1: PREV1 := 0 2: PREV2 := 1 3: do: 4: CUR := PREV1 + PREV2 5: PREV1 := PREV2 6: PREV2 := CUR 7: while (CUR < 10)
Este bucle no se puede paralelizar porque CUR depende de sí mismo (PREV2) y de PREV1, que se calculan en cada iteración del bucle. Dado que cada iteración depende del resultado de la anterior, no se pueden realizar en paralelo. A medida que el tamaño de un problema se hace más grande, la paralelización de datos disponible generalmente también lo hace.[22]
Paralelismo de tareas
[editar]El paralelismo de tareas es la característica de un programa paralelo en la que «cálculos completamente diferentes se pueden realizar en cualquier conjunto igual o diferente de datos».[21] Esto contrasta con el paralelismo de datos, donde se realiza el mismo cálculo en distintos o mismos grupos de datos. El paralelismo de tareas por lo general no escala con el tamaño de un problema.[22]
Hardware
[editar]Memoria y comunicación
[editar]La memoria principal en un ordenador en paralelo puede ser compartida —compartida entre todos los elementos de procesamiento en un único espacio de direcciones—, o distribuida —cada elemento de procesamiento tiene su propio espacio local de direcciones—.[23] El término memoria distribuida se refiere al hecho de que la memoria se distribuye lógicamente, pero a menudo implica que también se distribuyen físicamente. La memoria distribuida-compartida y la virtualización de memoria combinan los dos enfoques, donde el procesador tiene su propia memoria local y permite acceso a la memoria de los procesadores que no son locales. Los accesos a la memoria local suelen ser más rápidos que los accesos a memoria no local.

Las arquitecturas de ordenador en las que cada elemento de la memoria principal se puede acceder con igual latencia y ancho de banda son conocidas como arquitecturas de acceso uniforme a memoria (UMA). Típicamente, sólo se puede lograr con un sistema de memoria compartida, donde la memoria no está distribuida físicamente. Un sistema que no tiene esta propiedad se conoce como arquitectura de acceso a memoria no uniforme (NUMA). Los sistemas de memoria distribuidos tienen acceso no uniforme a la memoria.
Los sistemas informáticos suelen hacer uso de cachés, pequeños recuerdos rápidos ubicados cerca del procesador que almacenan las copias temporales de los valores de la memoria —cercano, tanto en el sentido físico y lógico—. Los sistemas computacionales paralelos tienen dificultades con las cachés y la posibilidad de una ejecución incorrecta del programa debido a que se puede almacenar el mismo valor en más de un lugar. Estos equipos requieren coherencia en la caché del sistema, generalmente realizan un seguimiento de los valores almacenados en caché y estratégicamente los eliminan, garantizando la correcta ejecución del programa. Bus sniffing es uno de los métodos más comunes para hacer el seguimiento de los valores a los que se está accediendo. El diseño de grandes sistemas de coherencia caché y de alto rendimiento es un problema muy difícil en arquitectura de computadores. Como resultado, las arquitecturas de memoria compartida no son tan escalables como los sistemas de memoria distribuida.[23]
La comunicación procesador-procesador y procesador-memoria se puede implementar en hardware de varias maneras: a través de memoria compartida —ya sea multipuerto o multiplexado—, un conmutador de barras cruzadas (crossbar switch), un bus compartido o una red interconectada de una gran variedad de topologías como estrella, anillo, árbol, hipercubo, hipercubo grueso —un hipercubo con más de un procesador en un nodo—, o de malla n-dimensional.
Las computadoras paralelas basadas en redes interconectadas deben tener algún tipo de enrutamiento para permitir el paso de mensajes entre nodos que no están conectados directamente. Es probable que el medio utilizado para la comunicación entre los procesadores de grandes máquinas multiprocesador sea jerárquico.
Clases de computadoras paralelas
[editar]Las computadoras paralelas se pueden clasificar de acuerdo con el nivel en el que el hardware soporta paralelismo. Esta clasificación es análoga a la distancia entre los nodos básicos de cómputo. Estos no son excluyentes entre sí, por ejemplo, los grupos de multiprocesadores simétricos son relativamente comunes.
Computación multinúcleo
[editar]Un procesador multinúcleo es un procesador que incluye múltiples unidades de ejecución (núcleos) en el mismo chip. Los procesadores superescalares pueden ejecutar múltiples instrucciones por ciclo de un flujo de instrucciones (hilo), a diferencia de este, un procesador multinúcleo puede ejecutar múltiples instrucciones por ciclo de secuencias de instrucciones múltiples. Cada núcleo en un procesador multinúcleo potencialmente puede ser superescalar, es decir, en cada ciclo, cada núcleo puede ejecutar múltiples instrucciones de un flujo de instrucciones.
El ''Multithreading'' simultáneo —de la cual Intel HyperThreading es el más conocido— era una forma de pseudo-multinúcleo. Un procesador con capacidad de multithreading simultáneo tiene una sola unidad de ejecución (núcleo), pero cuando esa unidad de ejecución está desocupada —por ejemplo, durante un error de caché—, se utiliza para procesar un segundo hilo. El microprocesador Cell de IBM, diseñado para su uso en la consola Sony PlayStation 3, es otro prominente procesador multinúcleo.
Multiprocesamiento simétrico
[editar]Un multiprocesador simétrico (SMP) es un sistema computacional con múltiples procesadores idénticos que comparten memoria y se conectan a través de un bus.[24] La contención del bus previene el escalado de esta arquitectura. Como resultado, los SMPs generalmente no comprenden más de 32 procesadores.[25] «Debido al pequeño tamaño de los procesadores y de la significativa reducción en los requisitos de ancho de banda de bus, tales multiprocesadores simétricos son extremadamente rentables, siempre que exista una cantidad suficiente de ancho de banda».[24]
Computación en clúster
[editar]
Un clúster es un grupo de ordenadores débilmente acoplados que trabajan en estrecha colaboración, de modo que en algunos aspectos pueden considerarse como un solo equipo.[26] Los clústeres se componen de varias máquinas independientes conectadas por una red. Mientras que las máquinas de un clúster tienen que ser simétricas, de no serlo, el balance de carga es más difícil de lograr. El tipo más común de clúster es el cluster Beowulf, que es un clúster implementado con múltiples ordenadores comerciales idénticos conectados a una red de área local TCP/IP Ethernet.[27] La tecnología Beowulf fue desarrollada originalmente por Thomas Sterling y Donald Becker. La gran mayoría de los superordenadores TOP500 son clústeres.[n. 4][28]
Procesamiento paralelo masivo
[editar]Un procesador paralelo masivo (MPP) es un solo equipo con varios procesadores conectados en red. Tienen muchas de las características de los clúster, pero cuentan con redes especializadas de interconexión —en tanto que las clústeres utilizan hardware estándar para la creación de redes—. Los MPPs también tienden a ser más grandes que los clústeres, con «mucho más» de 100 procesadores.[29] En un MPP, «cada CPU tiene su propia memoria y una copia del sistema operativo y la aplicación. Cada subsistema se comunica con los demás a través de un interconexión de alta velocidad».[30]

Computación distribuida
[editar]La computación distribuida es la forma más distribuida de la computación paralela. Se hace uso de ordenadores que se comunican a través de la Internet para trabajar en un problema dado. Debido al bajo ancho de banda y la latencia extremadamente alta de Internet, la computación distribuida normalmente sólo se refiere a problemas vergonzosamente paralelos. Se han creado muchas aplicaciones de computación distribuida, SETI@home y Folding@home son los ejemplos más conocidos.[31]
La mayoría de las aplicaciones de computación distribuida utilizan middleware, software que se encuentra entre el sistema operativo y la aplicación para administrar los recursos de red y estandarizar la interfaz de software. El más común es la Infraestructura Abierta de Berkeley para Computación en Red (BOINC). A menudo, los programas de computación distribuida hacen uso de «ciclos de repuesto», realizando cálculos cuando el procesador de un equipo está desocupado.
Computadoras paralelas especializadas
[editar]Dentro de la computación paralela, existen dispositivos paralelos especializados que generan interés. Aunque no son específicos para un dominio, tienden a ser aplicables sólo a unas pocas clases de problemas paralelos.
Cómputo reconfigurable con arreglos de compuertas programables
[editar]El cómputo reconfigurable es el uso de un arreglo de compuertas programables (FPGA) como coprocesador de un ordenador de propósito general. Un FPGA es, en esencia, un chip de computadora que puede reconfigurarse para una tarea determinada.
Los FPGAs se pueden programar con lenguajes de descripción de hardware como VHDL o Verilog. Sin embargo, los lenguajes de programación pueden ser tediosos. Varios vendedores han creado lenguajes «C a HDL» que tratan de emular la sintaxis y/o semántica del lenguaje de programación C, con el que la mayoría de los programadores están familiarizados. Los lenguajes «C a HDL» más conocidos son Mitrion-C, C Impulse, DIME C y C-Handel. También se pueden utilizar para este propósito subconjuntos específicos de SystemC basados en C++.
La decisión de AMD de abrir HyperTransport a otros fabricantes la ha convertido en la tecnología que permite la computación reconfigurable de alto rendimiento.[32] De acuerdo con Michael D'Amour R., Director de Operaciones de la DRC Computer Corporation, «cuando entramos en AMD, nos llamaban ladrones de zócalos. Ahora nos llaman socios».[32]
Cómputo de propósito general en unidades de procesamiento gráfico (GPGPU)
[editar]
El cómputo de propósito general en las unidades de procesamiento de gráficos (GPGPU) es una tendencia relativamente reciente en la investigación de ingeniería informática. Los GPUs son co-procesadores que han sido fuertemente optimizados para procesamiento de gráficos por computadora.[33] El procesamiento de gráficos por computadora es un campo dominado por operaciones sobre datos en paralelo, en particular de álgebra lineal y operaciones con matrices.
Al principio, los programas de GPGPU normalmente utilizaban el API de gráficos para ejecutar programas. Sin embargo, varios nuevos lenguajes de programación y plataformas se han construido para realizar cómputo de propósito general sobre GPUs, tanto Nvidia como AMD han liberado de entornos de programación con CUDA y Stream SDK, respectivamente. Otros lenguajes de programación de GPU incluyen: BrookGPU, PeakStream y RapidMind. Nvidia también ha lanzado productos específicos para la computación en su serie Tesla. El consorcio de tecnología Khronos Group ha lanzado OpenCL, que es un marco para la escritura de programas que se ejecutan en distintas plataformas conformadas por CPUs y GPUs. AMD, Apple, Intel, Nvidia y otros están apoyando OpenCL.
Circuitos integrados de aplicación específica
[editar]Se han diseñado varios circuitos integrados de aplicación específica (ASIC) para hacer frente a las aplicaciones paralelas.[34][35][36]
Debido a que un ASIC (por definición) es específico para una aplicación dada, puede ser completamente optimizado para esa aplicación. Como resultado, para una aplicación dada, un ASIC tiende a superar a un ordenador de propósito general. Sin embargo, los ASICs son creados con litografía de rayos X. Este proceso requiere una máscara, que puede ser extremadamente cara. Una máscara puede costar más de un millón de dólares.[n. 5][37] Mientras más pequeño sean los transistores necesarios para el chip, más cara será la máscara. Mientras tanto, el incremento del rendimiento en computadoras de propósito general —como se describe en la Ley de Moore— tiende a eliminar esta diferencia en sólo una o dos generaciones de chips.[32] El alto costo inicial, y la tendencia a ser superados por la ley de Moore, ha hecho inviable el uso de ASICs para la mayoría de las aplicaciones paralelas. Sin embargo, algunos han sido construidos, un ejemplo es el peta-flop RIKEN MDGRAPE-3 de la máquina que utiliza ASICs para la simulación de dinámica molecular.
Procesadores vectoriales
[editar]
Un procesador vectorial es un CPU o un sistema computacional que puede ejecutar la misma instrucción en grandes conjuntos de datos. «Los procesadores vectoriales tienen operaciones de alto nivel que trabajan sobre arreglos lineales de números o vectores. Un ejemplo de operación con vectores es: A = B × C, donde A, B, y C son vectores de 64 elementos, donde cada uno es un número de punto flotante de 64 bits».[38] Están estrechamente relacionadas con la clasificación SIMD de Flynn.[38]
Las computadoras Cray se volvieron famosas por su procesamiento de vectores en los años 1970 y 1980. Estos procesadores vectoriales hoy en día dejan su legado en las instrucciones SIMD, donde básicamente podemos realizar varios cálculos de forma simultánea en un par de ciclos de reloj. Los conjuntos de instrucciones de los procesadores modernos incluyen algunas instrucciones de procesamiento de vectores, por ejemplo: AltiVec y Streaming SIMD Extensions (SSE).
Software
[editar]Lenguajes de programación en paralelo
[editar]Los lenguajes de programación concurrentes, bibliotecas, APIs y modelos de programación paralela han sido creados para la programación de computadores paralelos. Estos generalmente se pueden dividir en clases basadas en las suposiciones que se hacen sobre la arquitectura de memoria subyacente: compartida, distribuida, o compartida-distribuida. Los lenguajes de programación de memoria compartida se comunican mediante la manipulación de variables en la memoria compartida. En la arquitectura con memoria distribuida se utiliza el paso de mensajes. POSIX Threads y OpenMP son dos de las API más utilizadas con la memoria compartida, mientras que Message Passing Interface (MPI) «Interfaz de Paso de Mensajes» es el API más utilizado en los sistemas de paso de mensajes.[n. 6][39] El concepto «valor futuro» es muy utilizado en la programación de programas paralelos, donde una parte de un programa promete proporcionar un dato requerido a otra parte del programa en un tiempo futuro.
Las empresas CAPS entreprise y Pathscale están intentando convertir las directivas de HMPP (Hybrid Multicore Parallel Programming) en un estándar abierto denominado OpenHMPP. El modelo de programación OpenHMPP basado en directivas ofrece una sintaxis para descargar de manera eficiente los cálculos sobre aceleradores de hardware y optimizar el movimiento de datos hacia y desde la memoria del hardware. Las directivas OpenHMPP describen llamadas a procedimientos remotos (RPC) en un dispositivo acelerador —por ejemplo el GPU— o de forma más general un conjunto de núcleos. Las directivas permiten anotar código C o Fortran para describir dos grupos de funcionalidades: la descarga de los procedimientos en un dispositivo remoto y la optimización de las transferencias de datos entre la memoria principal de la CPU y la memoria del acelerador.
Paralelización automática
[editar]La paralelización automática de un programa secuencial por un compilador es el santo grial de la computación paralela. A pesar de décadas de trabajo por parte de los investigadores, la paralelización automática ha tenido un éxito limitado.[n. 7][40]
Los principales lenguajes de programación en paralelo permanecen explícitamente paralelos o en el mejor de los casos parcialmente implícitos, en los que un programador le da al compilador directivas de paralelización. Existen pocos lenguajes de programación paralelos totalmente implícitos: SISAL, Parallel Haskell, y (para FPGAs) Mitrion C.
Punto de control
[editar]Mientras un sistema computacional crece en complejidad, el tiempo medio entre fallos por lo general disminuye. Un punto de control de aplicación es una técnica mediante la cual el sistema informático toma una «instantánea» de la aplicación, un registro de todas las asignaciones actuales de recursos y estados variables, semejante a un volcado de memoria, esta información se puede utilizar para restaurar el programa si el equipo falla. Disponer de un punto de control significa que el programa puede reiniciar desde este y no desde el principio. Mientras que los puntos de control proporcionan beneficios en una variedad de situaciones, son especialmente útiles en los sistemas altamente paralelos con un gran número de procesadores que son utilizados en la computación de altas prestaciones.[41]
Comandos paralelos
[editar]Los procesos de un comando paralelo deben ser inconexos de cualquier otro comando esto considerando que no se menciona ninguna variable que se produzca como una variable destino en cualquier otro proceso. Los subíndices son constantes enteras que sirven como nombre para la lista de comandos. Entonces un proceso cuyos subíndices de etiquetas incluyen uno o más rangos para una serie de procesos, cada uno con la misma etiqueta y lista de comandos cada uno tiene una combinación de diferentes valores que son sustituidos por las variables combinadas. Un comando paralelo especifica la ejecución concurrente de sus procesos constituyentes. Todos comienzan simultáneamente y el comando paralelo termina con éxito solo siempre y cuando todos hayan terminado con éxito.
Métodos algorítmicos
[editar]Mientras que las computadoras paralelas se hacen más grandes y más rápidas, se hace factible resolver problemas que antes tardaban demasiado tiempo en ejecutarse. La computación en paralelo se utiliza en una amplia gama de campos, desde la bioinformática (plegamiento de proteínas y análisis de secuencia) hasta la economía (matemática financiera). Los tipos de problemas encontrados comúnmente en las aplicaciones de computación en paralelo son:[42]
- Álgebra lineal densa
- Álgebra lineal dispersa
- Métodos espectrales (tales como la transformada rápida de Fourier de Cooley-Tukey)
- Problemas de n-cuerpos (tales como la simulación Barnes-Hut)
- Problemas de grids estructurados (métodos de Lattice Boltzmann)
- Problemas de grids no estructurados (tales como los encontrados en el análisis de elementos finitos)
- Simulación de Montecarlo
- Lógica combinacional (por ejemplo, técnicas criptográficas de fuerza bruta)
- Recorridos en grafos (por ejemplo, los algoritmos de ordenamiento)
- Programación dinámica
- Métodos de Ramificación y poda
- Modelos en grafos (tales como la detección de modelos ocultos de Markov y la construcción de redes bayesianas)
- Simulación de autómatas finitos
Historia
[editar]
Los orígenes del verdadero paralelismo (MIMD) se remontan a Federico Luigi, Menabrea Conte y su «Bosquejo de la máquina analítica inventada por Charles Babbage».[44][45] IBM introdujo el IBM 704 en 1954, a través de un proyecto en el que Gene Amdahl fue uno de los principales arquitectos. Se convirtió en el primer equipo disponible en el mercado que utilizaba comandos aritméticos de punto flotante totalmente automáticos.[46]
En abril de 1958, S. Gill (Ferranti) analizó la programación en paralelo y la necesidad de la ramificación y la espera.[47] También en 1958, los investigadores de IBM John Cocke y Daniel Slotnick discutieron por primera vez el uso del paralelismo en cálculos numéricos.[48] Burroughs Corporation presentó la D825 en 1962, un equipo de cuatro procesadores que accede a un máximo de 16 módulos de memoria a través de un conmutador de barras cruzadas.[49] En 1967, Amdahl y Slotnick publicaron un debate sobre la viabilidad de procesamiento en paralelo en la Conferencia de la Federación Americana de Sociedades de Procesamiento de la Información.[48] Fue durante este debate que la Ley de Amdahl fue acuñada para definir los límites de aceleración que se pueden alcanzar debido al paralelismo.
En 1969, la compañía estadounidense Honeywell introdujo su primer sistema Multics, un sistema con multiprocesador simétrico capaz de ejecutar hasta ocho procesadores en paralelo.[48] En 1970, C.mmp, un proyecto en la Universidad Carnegie Mellon con varios procesadores, fue «uno de los primeros multiprocesadores con más de unos pocos procesadores».[45] «El primer bus con conexión multi-procesador y caché espía fue el Synapse N+1 en el año 1984».[45]
Las computadoras paralelas SIMD se remontan a la década de 1970. La motivación detrás de las primeras computadoras SIMD era amortizar el retardo de la compuerta de la unidad de control del procesador en múltiples instrucciones.[50] En 1964, Slotnick había propuesto la construcción de un ordenador masivamente paralelo para el Laboratorio Nacional Lawrence Livermore.[48] Su diseño fue financiado por la Fuerza Aérea de los Estados Unidos, que fue el primer esfuerzo por lograr la computación en paralelo SIMD.[48] La clave de su diseño fue un paralelismo bastante alto, con hasta 256 procesadores, lo que permitió que la máquina trabajara en grandes conjuntos de datos en lo que más tarde sería conocido como el procesamiento de vectores. Sin embargo, ILLIAC IV fue llamado «el más infame de los superordenadores», pues solo se había completado una cuarta parte del proyecto. Tardó 11 años, costando casi cuatro veces la estimación original.[n. 8][43] Cuando estaba listo para ejecutar una aplicación real por primera vez en 1976, fue superado por supercomputadoras comerciales, como el Cray-1.
Computadora Paralela
[editar]Es una computadora con múltiples procesadores, donde cada procesador trabaja sobre una sección del problema y los procesadores permiten el intercambio de información con otros procesadores.
Ventajas de las computadoras paralelas
[editar]- Rendimiento y memoria.
Son capaces de resolver problemas que:
- Requieren de una solución rápida.
- Requieren de una gran capacidad de memoria.
Beneficios de las computadoras paralelas
[editar]- Datos:
- Dominios grandes. - Búsqueda de soluciones en regiones grandes. - Muchas partículas.
- Pasos de tiempo:
- Largas ejecuciones. - Mejor resolución/granularidad temporal.
- Ejecución (rápida):
- Tiempos más cortos - Muchas soluciones al mismo tiempo. - Largas simulaciones en tiempo real.
Notas
[editar]- ↑ Las técnicas principales para lograr estas mejoras de rendimiento —mayor frecuencia de reloj y arquitecturas cada vez más inteligentes y complejas— están golpeando la llamada power wall. La industria informática ha aceptado que los futuros aumentos en rendimiento deben provenir en gran parte del incremento del número de procesadores (o núcleos) en una matriz, en vez de hacer más rápido un solo núcleo.
- ↑ Antigua [sabiduría convencional]: La energía es gratuita y los transistores son caros. Nueva [sabiduría convencional]: la energía es cara y los transistores son "gratuitos"
- ↑ Antigua [sabiduría convencional]: incrementar la frecuencia de reloj es el método principal de mejorar el rendimiento del procesador. Nueva [sabiduría convencional]: el incremento del paralelismo es el método principal para mejorar el rendimiento del procesador... Incluso los representantes de Intel, una empresa asociada a la posición: "mayor velocidad de reloj es mejor", advirtió que los enfoques tradicionales para aumentar el rendimiento a través de la maximización de la velocidad de reloj han sido empujados hasta el límite.
- ↑ En los TOP500 Supercomputing Sites los clústeres alcanzan el 74.60% de las máquinas en la lista.
- ↑ ...el costo de una máscara y tarjeta de prueba —que es mucho más de $1 millón en los 90nm— crea un amortiguador importante en la innovación basada en semiconductores...
- ↑ Se referencia la Interfaz de Paso de Mensajes como "la interfaz dominante de HPC"
- ↑ Sin embargo, el santo grial de la investigación —paralelización automática de programas en serie— todavía tiene que materializarse. Aunque la paralelización automática de ciertas clases de algoritmos se ha demostrado, este éxito ha sido en gran parte limitado a aplicaciones científicas y numéricas con control de flujo predecible —por ejemplo, las estructuras de bucle anidado con un recuento de iteración estáticamente determinado— y patrones de acceso a memoria analizables estáticamente —por ejemplo, recorridos en grandes arreglos multidimensionales de datos de punto flotante—.
- ↑ Aunque tuvo éxito en impulsar varias tecnologías útiles en proyectos posteriores, el IV ILLIAC no triunfó como ordenador. Los costos se ascendieron de los $8 millones estimados en 1966 a $31 millones en 1972, a pesar de la construcción de sólo un cuarto de la máquina planeada... Fue tal vez la más infame de las supercomputadoras. El proyecto comenzó en 1965 y ejecutó su primera aplicación real en 1976
Referencias
[editar]- ↑ Gottlieb, Allan; Almasi, George S. (1989). Highly parallel computing (en inglés). Redwood City, California.: Benjamin/Cummings. ISBN 0-8053-0177-1.
- ↑ "Parallel Computing Research at Illinois: The UPCRC Agenda" (pdf) (en inglés). Universidad de Illinois en Urbana-Champaign. noviembre de 2008. Archivado desde el original el 9 de diciembre de 2008.
- ↑ "The Landscape of Parallel Computing Research: A View from Berkeley" (pdf) (en inglés) (UCB/EECS-2006-183). Universidad de California, Berkeley. 18 de diciembre de 2006.
- ↑ "The Landscape of Parallel Computing Research: A View from Berkeley" (pdf) (en inglés) (UCB/EECS-2006-183). Universidad de California, Berkeley. 18 de diciembre de 2006.
- ↑ Hennessy, John L.; Patterson, David A., Larus, James R. (1999). Computer organization and design : the hardware/software interface (en inglés) (2da edición). San Francisco: Kaufmann. ISBN 1-55860-428-6.
- ↑ a b Barney, Blaise. «Introduction to Parallel Computing» (en inglés). Lawrence Livermore National Laboratory. Consultado el 9 de noviembre de 2007.
- ↑ Hennessy, John L.; Patterson, David A. (2002). Computer architecture a quantitative approach. (en inglés) (3ra edición). San Francisco, California: International Thomson. p. 43. ISBN 1-55860-724-2.
- ↑ Rabaey, Jan M. (1996). Digital integrated circuits : a design perspective (en inglés). Upper Saddle River, N.J.: Prentice-Hall. p. 235. ISBN 0-13-178609-1.
- ↑ Flynn, Laurie J. (8 de mayo de 2004). «Intel Halts Development Of 2 New Microprocessors». New York Times (en inglés). Consultado el 5 de junio de 2012.
- ↑ Moore, Gordon E. (1965). «Cramming more components onto integrated circuits» (pdf). Electronics Magazine (en inglés). Archivado desde el original el 18 de febrero de 2008. Consultado el 11 de noviembre de 2006.
- ↑ Amdahl, Gene M. (18-20 de abril de 1967). «Validity of the single processor approach to achieving large scale computing capabilities». Proceeding AFIPS '67 (Spring) (en inglés): 483-485. doi:10.1145/1465482.1465560.
- ↑ Brooks, Frederick P. (1996). The mythical man month essays on software engineering (en inglés) (Anniversary, repr. with corr., 5 edición). Reading, Mass.: Addison-Wesley. ISBN 0-201-83595-9.
- ↑ Gustafson, John L. (mayo de 1988). «Reevaluating Amdahl's law». Communications of the ACM (en inglés) 31 (5): 532-533. doi:10.1145/42411.42415. Archivado desde el original el 27 de septiembre de 2007.
- ↑ Bernstein, A. J. (1 de octubre de 1966). «Analysis of Programs for Parallel Processing». IEEE Transactions on Electronic Computers (en inglés). EC-15 (5): 757-763. doi:10.1109/PGEC.1966.264565.
- ↑ Roosta, Seyed H. (2000). Parallel processing and parallel algorithms: theory and computation (en inglés). New York, NY [u.a.]: Springer. p. 114. ISBN 0-387-98716-9.
- ↑ Lamport, Leslie (1 de septiembre de 1979). «How to Make a Multiprocessor Computer That Correctly Executes Multiprocess Programs». IEEE Transactions on Computers (en inglés). C-28 (9): 690-691. doi:10.1109/TC.1979.1675439.
- ↑ Patterson y Hennessy, p. 748.
- ↑ Culler et al. p. 15.
- ↑ Culler et al. p. 15.
- ↑ Patt, Yale (2004). The Microprocessor Ten Years From Now: What Are The Challenges, How Do We Meet Them? (wmv) (en inglés). Carnegie Mellon University. Archivado desde el original el 14 de abril de 2008. Consultado el 7 de noviembre de 2007.
- ↑ a b Culler et al. p. 124.
- ↑ a b Culler et al. p. 125.
- ↑ a b Patterson y Hennessy, p. 713.
- ↑ a b Hennessy y Patterson, p. 549.
- ↑ Patterson y Hennessy, p. 714.
- ↑ What is clustering? «Webopedia computer dictionary» (en inglés). Consultado el 7 de noviembre de 2007.
- ↑ «Beowulf definition» (en inglés). PC Magazine. Archivado desde el original el 10 de octubre de 2012. Consultado el 7 de noviembre de 2007.
- ↑ «Architecture share for 06/2007» (en inglés). Archivado desde el original el 14 de noviembre de 2007. Consultado el 7 de noviembre de 2007.
- ↑ Hennessy y Patterson, p. 537.
- ↑ MPP Definition (en inglés). PC Magazine. Archivado desde el original el 11 de mayo de 2013. Consultado el 7 de noviembre de 2007.
- ↑ Kirkpatrick, Scott (2003). «COMPUTER SCIENCE: Rough Times Ahead». Science (en inglés) 299 (5607): 668-669. PMID 12560537. doi:10.1126/science.1081623.
- ↑ a b c Michael R. Chief Operating Officer, DRC Computer Corporation, Invited speaker D'Amour (28 de febrero de 2007). Standard Reconfigurable Computing (en inglés). Universidad de Delaware.
- ↑ Sha'Kia, Boggan; Pressel, Daniel M. (agosto de 2007). GPUs: An Emerging Platform for General-Purpose Computation ARL-SR-154 (pdf) (en inglés). U.S. Army Research Lab. Archivado desde el original el 25 de diciembre de 2016. Consultado el 7 de noviembre de 2007.
- ↑ Maslennikov, Oleg (2002). «Systematic Generation of Executing Programs for Processor Elements in Parallel ASIC or FPGA-Based Systems and Their Transformation into VHDL-Descriptions of Processor Element Control Units». Lecture Notes in Computer Science 2328/2002 (en inglés): 272. Archivado desde el original el 11 de febrero de 2020. Consultado el 19 de diciembre de 2012.
- ↑ Shimokawa, Y.; Y. Fuwa and N. Aramaki (18 al 21 de noviembre de 1991). «A parallel ASIC VLSI neurocomputer for a large number of neurons and billion connections per second speed». International Joint Conference on Neural Networks (en inglés) 3: 2162-2167. ISBN 0-7803-0227-3. doi:10.1109/IJCNN.1991.170708.
- ↑ Acken, Kevin P.; Irwin, Mary Jane; Owens, Robert M. (1 de enero de 1998). The Journal of VLSI Signal Processing (en inglés) 19 (2): 97-113. doi:10.1023/A:1008005616596.
- ↑ Scoping the Problem of DFM in the Semiconductor Industry (en inglés). Universidad de California, San Diego. 21 de junio de 2004. Archivado desde el original el 31 de enero de 2008.
- ↑ a b Patterson y Hennessy, p. 751.
- ↑ «Sidney Fernbach Award given to MPI inventor Bill Gropp» (en inglés). Archivado desde el original el 25 de julio de 2011. Consultado el 19 de diciembre de 2012.
- ↑ Shen, John Paul; Mikko H. Lipasti (2004). Modern processor design : fundamentals of superscalar processors (en inglés) (1ra edición). Dubuque, Iowa: McGraw-Hill. p. 561. ISBN 0-07-057064-7.
- ↑ Padua, David (2011). Encyclopedia of Parallel Computing (en inglés) 4. p. 265. ISBN 0387097651.
- ↑ Krste, et al., Asanovic (18 de diciembre de 2006). The Landscape of Parallel Computing Research: A View from Berkeley (pdf) (en inglés) (Technical Report No. UCB/EECS-2006-183). Universidad de California, Berkeley. pp. 17-19.
- ↑ a b Hennessy, Patterson. (en inglés). pp. 749-50. Falta el
|título=(ayuda) - ↑ Conte Menabrea Menabrea, L. F., Federico Luigi (1842). «Sketch of the Analytic Engine Invented by Charles Babbage» (en inglés). Bibliothèque Universelle de Genève. Consultado el 7 de noviembre de 2007.
- ↑ a b c Patterson y Hennessy, p. 753.
- ↑ da Cruz, Frank (2003). «Columbia University Computing History: The IBM 704» (en inglés). Columbia University. Consultado el 1 de agosto de 2008.
- ↑ Gill, S. (abril de 1958). Parallel Programming (en inglés) 1. Sociedad Británica de Computación: The Computer Journal. pp. 2-10.
- ↑ a b c d e Wilson, Gregory V (1994). «The History of the Development of Parallel Computing» (en inglés). Virginia Tech/Norfolk State University, Interactive Learning with a Digital Library in Computer Science. Consultado el 1 de agosto de 2008.
- ↑ Anthes, Gry (19 de noviembre de 2001). «The Power of Parallelism». Computerworld (en inglés). Archivado desde el original el 4 de junio de 2008. Consultado el 1 de agosto de 2008.
- ↑ Patterson y Hennessy, p. 749.
Bibliografía
[editar]- Singh, David Culler; J.P. (1997). Parallel computer architecture (en inglés) (Nachdr. edición). San Francisco: Morgan Kaufmann Publ. p. 15. ISBN 1-55860-343-3.
- Hennessy, John L.; Patterson, David A. (27 de septiembre de 2006). Computer Architecture: A Quantitative Approach [Arquitectura de computadoras: un enfoque cuantitativo] (en inglés) (4ta edición). Morgan Kaufmann. ISBN 0123704901.
- Patterson, David A.; Hennessy, John L. (9 de noviembre de 2011). Computer Organization and Design, Fourth Edition: The Hardware/Software Interface [Organización y diseño de computadoras, 4ta edición: La interfaz hardware/software] (en inglés) (4ta edición). Morgan Kaufmann. ISBN 0123747503.
Lectura adicional
[editar]- Rodriguez, C.; Villagra, M.; Baran, B. (29 de agosto de 2008). «Asynchronous team algorithms for Boolean Satisfiability». Bio-Inspired Models of Network, Information and Computing Systems, 2007. Bionetics 2007. 2nd (en inglés): 66-69. doi:10.1109/BIMNICS.2007.4610083.
Enlaces externos
[editar]Wikilibros alberga un libro o manual sobre Distributed Systems.
Wikimedia Commons alberga una galería multimedia sobre Computación paralela.
- OpenHMPP, A New Standard for Manycore (en inglés)
- Internet Parallel Computing Archive (en inglés)
- Universal Parallel Computing Research Center (en inglés)
- Designing and Building Parallel Programs, by Ian Foster (en inglés)
- Go Parallel: Translating Multicore Power into Application Performance (en inglés)
- What makes parallel programming hard? (en inglés)
- Course in Parallel Computing at University of Wisconsin-Madison (en inglés)
- Parallel and distributed Grobner bases computation in JAS (en inglés)
- Parallel Computing Works Free On-line Book Archivado el 27 de julio de 2011 en Wayback Machine. (en inglés)
- Comparing programmability of Open MP and pthreads (en inglés)
- Lawrence Livermore National Laboratory: Introduction to Parallel Computing (en inglés)
- Course in Parallel Programming at Columbia University (in collaboration with IBM T.J Watson X10 project) (en inglés)
- Frontiers of Supercomputing Free On-line Book Covering topics like algorithms and industrial applications (en inglés)
- Parallel processing topic area at IEEE Distributed Computing Online (en inglés)
- Esta obra contiene una traducción derivada de «Parallel_computing» de Wikipedia en inglés, publicada por sus editores bajo la Licencia de documentación libre de GNU y la Licencia Creative Commons Atribución-CompartirIgual 4.0 Internacional.
| Control de autoridades |
|
|---|
Datos: Q232661