Algorithmique
L'algorithmique est l'étude et la production de règles et techniques qui sont impliquées dans la définition et la conception d'algorithmes, c'est-à-dire de processus systématiques de résolution d'un problème permettant de décrire précisément des étapes pour résoudre un problème algorithmique.
Étymologie
[modifier | modifier le code]Le mot « algorithme » vient du nom du mathématicien Al-Khwârizmî[1] (latinisé au Moyen Âge en Algoritmi), qui, au IXe siècle écrivit le premier ouvrage systématique donnant des solutions aux équations linéaires et quadratiques. Le h muet, non justifié par l'étymologie, vient d’une déformation par rapprochement avec le grec ἀριθμός (arithmós)[2]. « Algorithme » a donné « algorithmique ». Le synonyme « algorithmie », vieux mot utilisé par exemple par Wronski en 1811[3], est encore parfois utilisé[4].
Histoire
[modifier | modifier le code]
Antiquité
[modifier | modifier le code]Les premiers algorithmes dont on a retrouvé des descriptions datent des Babyloniens, au IIIe millénaire av. J.-C.. Ils décrivent des méthodes de calcul et des résolutions d'équations à l'aide d'exemples[5],[6].
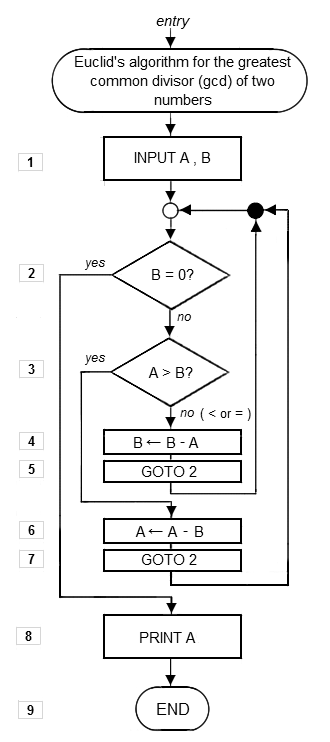
Un algorithme célèbre est celui qui se trouve dans le livre 7 des Éléments d'Euclide, et appelé algorithme d'Euclide. Il permet de trouver le plus grand diviseur commun, ou PGCD, de deux nombres. Un point particulièrement remarquable est qu’il contient explicitement une itération et que les propositions 1 et 2 démontrent sa correction.
C'est Archimède qui proposa le premier un algorithme pour le calcul de π[7].
Étude systématique
[modifier | modifier le code]Le premier à avoir systématisé des algorithmes est le mathématicien perse Al-Khwârizmî, actif entre 813 et 833. Dans son ouvrage Abrégé du calcul par la restauration et la comparaison, il étudie toutes les équations du second degré et en donne la résolution par des algorithmes généraux. Il utilise des méthodes semblables à celles des Babyloniens, mais se différencie par ses explications systématiques là où les Babyloniens donnaient seulement des exemples.
Le savant andalou Averroès (1126-1198) évoque une méthode de raisonnement où la thèse s’affine étape par étape, itérativement, jusqu’à une certaine convergence et ceci conformément au déroulement d’un algorithme. À la même époque, au XIIe siècle, le moine Adelard de Bath introduit le terme latin de algorismus, par référence au nom de Al Khuwarizmi. Ce mot donne algorithme en français en 1554.
Au XVIIe siècle, on pourrait entrevoir une certaine allusion à la méthode algorithmique chez René Descartes dans la méthode générale proposée par le Discours de la méthode (1637), notamment quand, en sa deuxième partie, le mathématicien français propose de « diviser chacune des difficultés que j’examinerois, en autant de parcelles qu’il se pourroit, et qu’il seroit requis pour les mieux résoudre ». Sans évoquer explicitement les concepts de boucle, d’itération ou de dichotomie, l’approche de Descartes prédispose la logique à accueillir le concept de programme, mot qui naît en français en 1677.
En 1843 , la mathématicienne et pionnière des sciences informatique Ada Lovelace, fille de Lord Byron et assistante de Charles Babbage réalise la première implémentation d'un algorithme sous forme de programme (calcul des nombres de Bernoulli)[8].
Le dixième problème de Hilbert qui fait partie de la liste des 23 problèmes posés par David Hilbert en 1900 à Paris est clairement un problème algorithmique. En l'occurrence, la réponse est qu'il n'y a pas d'algorithme répondant au problème posé.
L'époque contemporaine
[modifier | modifier le code]L’algorithmique des XXe et XXIe siècles a pour fondement mathématique des formalismes, par exemple celui des machines de Turing, qui permettent de définir précisément ce qu'on entend par « étapes », par « précis » et par « non ambigu » et qui donnent un cadre scientifique pour étudier les propriétés des algorithmes. Cependant, suivant le formalisme choisi on obtient des approches algorithmiques différentes pour résoudre un même problème. Par exemple l'algorithmique récursive, l'algorithmique parallèle ou l’informatique quantique donnent lieu à des présentations d'algorithmes différentes de celles de l'algorithmique itérative.
L'algorithmique s'est surtout développée dans la deuxième moitié du XXe siècle, comme support conceptuel de la programmation des ordinateurs, dans le cadre du développement de l'informatique pendant cette période. Donald Knuth, auteur du traité The Art of Computer Programming qui décrit de très nombreux algorithmes, a contribué, avec d'autres, à poser les fondements mathématiques de leur analyse.
Vocabulaire
[modifier | modifier le code]Le substantif algorithmique désigne l'ensemble des méthodes permettant de créer des algorithmes. Le terme est également employé comme adjectif.
Un algorithme énonce une solution à un problème sous la forme d’un enchaînement d’opérations à effectuer.
Les informaticiens utilisent fréquemment l’anglicisme implémentation pour désigner la mise en œuvre de l'algorithme dans un langage de programmation. Cette implémentation réalise la transcription des opérations constitutives de l’algorithme et précise la façon dont ces opérations sont invoquées. Cette écriture en langage informatique, est aussi fréquemment désignée par le terme de « codage »[9]. On parle de « code source » pour désigner le texte, constituant le programme, réalisant l’algorithme. Le code est plus ou moins détaillé selon le niveau d’abstraction du langage utilisé, de même qu'une recette de cuisine doit être plus ou moins détaillée selon l’expérience du cuisinier.
Étude formelle
[modifier | modifier le code]De nombreux outils formels ou théoriques ont été développés pour décrire les algorithmes, les étudier, exprimer leurs qualités, pouvoir les comparer :
- ainsi, pour décrire les algorithmes, des structures algorithmiques ont été mises en évidence : structures de contrôle et structures de données ;
- pour justifier de la qualité des algorithmes, les notions de correction, de complétude et de terminaison ont été mises en place ;
- enfin, pour comparer les algorithmes, une théorie de la complexité des algorithmes a été définie.
Structures algorithmiques
[modifier | modifier le code]Les concepts en œuvre en algorithmique, par exemple selon l'approche de N. Wirth pour les langages les plus répandus (Pascal, C, etc.), sont en petit nombre. Ils appartiennent à deux classes :
- les structures de contrôle :
- séquences,
- conditionnelles,
- boucles ;
- les structures de données :
- constantes,
- variables,
- tableaux ;
- structures récursives (listes, arbres, graphes).
Ce découpage est parfois difficile à percevoir pour certains langages (Lisp, Prolog…) plus basés sur la notion de récursivité où certaines structures de contrôle sont implicites et, donc, semblent disparaître.
Correction, complétude, terminaison
[modifier | modifier le code]Ces trois notions « correction », « complétude », « terminaison » sont liées, et supposent qu'un algorithme est écrit pour résoudre un problème.
La terminaison est l'assurance que l'algorithme terminera en un temps fini. Les preuves de terminaison font habituellement intervenir une fonction entière positive strictement décroissante à chaque « pas » de l'algorithme.
Étant donné la garantie qu'un algorithme terminera, la preuve de correction doit apporter l'assurance que si l'algorithme termine en donnant un résultat, alors ce résultat est effectivement une solution au problème posé. Les preuves de correction font habituellement intervenir une spécification logique que doivent vérifier les solutions du problème. La preuve de correction consiste donc à montrer que les résultats de l'algorithme vérifient cette spécification.
La preuve de complétude garantit que, pour un espace de problèmes donné, l'algorithme, s'il termine, donnera l'ensemble des solutions de l'espace du problème. Les preuves de complétude demandent à identifier l'espace du problème et l'espace des solutions pour ensuite montrer que l'algorithme produit bien le second à partir du premier.
Complexité algorithmique
[modifier | modifier le code]Les principales notions mathématiques dans le calcul du coût d’un algorithme précis sont les notions de domination (notée O(f(n)), « grand o »), où f est une fonction mathématique de n, variable désignant la quantité d’informations (en bits, en nombre d’enregistrements, etc.) manipulée dans l’algorithme. En algorithmique on trouve souvent des complexités du type :
| Notation | Type de complexité |
|---|---|
| complexité constante (indépendante de la taille de la donnée) | |
| complexité logarithmique | |
| complexité linéaire | |
| complexité quasi linéaire | |
| complexité quadratique | |
| complexité cubique | |
| complexité polynomiale | |
| complexité quasi polynomiale | |
| complexité exponentielle | |
| complexité factorielle |
Sans entrer dans les détails mathématiques, le calcul de l’efficacité d’un algorithme (sa complexité algorithmique) consiste en la recherche de deux quantités importantes. La première quantité est l’évolution du nombre d’instructions de base en fonction de la quantité de données à traiter (par exemple, pour un algorithme de tri, il s'agit du nombre de données à trier), que l’on privilégiera sur le temps d'exécution mesuré en secondes (car ce dernier dépend de la machine sur laquelle l'algorithme s'exécute). La seconde quantité estimée est la quantité de mémoire nécessaire pour effectuer les calculs. Baser le calcul de la complexité d’un algorithme sur le temps ou la quantité effective de mémoire qu’un ordinateur particulier prend pour effectuer ledit algorithme ne permet pas de prendre en compte la structure interne de l’algorithme, ni la particularité de l’ordinateur : selon sa charge de travail, la vitesse de son processeur, la vitesse d’accès aux données, l’exécution de l’algorithme (qui peut faire intervenir le hasard) ou son organisation de la mémoire, le temps d’exécution et la quantité de mémoire ne seront pas les mêmes.
Souvent, on examine les performances « au pire », c'est-à-dire dans les configurations telles que le temps d'exécution ou l'espace mémoire est le plus grand. Il existe également un autre aspect de l'évaluation de l'efficacité d'un algorithme : les performances « en moyenne ». Cela suppose d'avoir un modèle de la répartition statistique des données de l'algorithme, tandis que la mise en œuvre des techniques d'analyse implique des méthodes assez fines de combinatoire et d'évaluation asymptotique, utilisant en particulier les séries génératrices et des méthodes avancées d'analyse complexe. L'ensemble de ces méthodes est regroupé sous le nom de combinatoire analytique.
On trouvera dans l’article sur la théorie de la complexité des algorithmes d’autres évaluations de la complexité qui vont en général au-delà des valeurs proposées ci-dessus et qui classifient les problèmes algorithmiques (plutôt que les algorithmes) en classes de complexité.
Quelques indications sur l’efficacité des algorithmes et ses biais
[modifier | modifier le code]L'efficacité algorithmique n’est souvent connue que de manière asymptotique, c’est-à-dire pour de grandes valeurs du paramètre n. Lorsque ce paramètre est suffisamment petit, un algorithme de complexité asymptotique plus grande peut en pratique être plus efficace. Ainsi, pour trier un tableau de 30 lignes (c’est un paramètre de petite taille), il est inutile d’utiliser un algorithme évolué comme le tri rapide (l’un des algorithmes de tri asymptotiquement les plus efficaces en moyenne) : l’algorithme de tri le plus simple à écrire sera suffisamment efficace.
Entre deux algorithmes informatiques de complexité identique, on utilisera celui dont l’occupation mémoire est moindre. L’analyse de la complexité algorithmique peut également servir à évaluer l’occupation mémoire d’un algorithme. Enfin, le choix d’un algorithme plutôt qu’un autre doit se faire en fonction des données que l’on s’attend à lui fournir en entrée. Ainsi, le tri rapide, lorsque l’on choisit le premier élément comme pivot, se comporte de façon désastreuse si on l’applique à une liste de valeurs déjà triée. Il n’est donc pas judicieux de l’utiliser si on prévoit que le programme recevra en entrée des listes déjà presque triées ou alors il faudra choisir le pivot aléatoirement.
D'autres paramètres à prendre en compte sont notamment :
- les biais intrinsèques (acceptés ou involontaires) de nombreux algorithmes peuvent tromper les utilisateurs ou systèmes d'intelligence artificielle, de machine learning, de diagnostic informatique, mécanique, médical, de prévision, de prévention, de sondages ou d'aide à la décision (notamment pour les réseaux sociaux, l'éducation [ex : parcoursup ], la médecine, la justice, la police, l'armée, la politique, l'embauche…) prenant mal en compte ou pas du tous ces biais[10]. En 2019, des chercheurs de Télécom ParisTech ont produit un rapport inventoriant les principaux biais connus, et quelques pistes de remédiation[10]
- la localité de l’algorithme. Par exemple pour un système à mémoire virtuelle ayant peu de mémoire vive (par rapport au nombre de données à traiter), le tri rapide sera normalement plus efficace que le tri par tas car le premier ne passe qu’une seule fois sur chaque élément de la mémoire tandis que le second accède à la mémoire de manière discontinue (ce qui augmente le risque de swapping).
- certains algorithmes (ceux dont l'analyse de complexité est dite amortie), pour certaines exécutions de l’algorithme (cas marginaux), présentent une complexité qui sera très supérieure au cas moyen, mais ceci sera compensé par des exécutions rendues efficaces du même algorithme dans une suite d'invocations de cet algorithme.
- l'Analyse lisse d'algorithme, qui mesure les performances des algorithmes sur les pires cas, mais avec une légère perturbation des instances. Elle explique pourquoi certains algorithmes analysés comme inefficaces autrement, sont en fait efficaces en pratique. L'algorithme du simplexe est un exemple d'un algorithme qui se comporte bien pour l'analyse lisse.
Approches pratiques
[modifier | modifier le code]L'algorithmique a développé quelques stratégies pour résoudre les problèmes :
- algorithme glouton : un premier algorithme peut souvent être proposé en étudiant le problème très progressivement : on résout chaque sous-problème localement en espérant que l'ensemble de leurs résultats composera bien une solution du problème global. On parle alors d'algorithme glouton. L'algorithme glouton n'est souvent qu'une première étape dans la rédaction d'un algorithme plus performant ;
- diviser pour régner : pour améliorer les performances des algorithmes, une technique usuelle consiste à diviser les données d'un problème en sous-ensembles de tailles plus petites, jusqu'à obtenir des données que l'algorithme pourra traiter au cas par cas. Une seconde étape dans ces algorithmes consiste à « fusionner » les résultats partiels pour obtenir une solution globale. Ces algorithmes sont souvent associés à la récursivité ;
- recherche exhaustive (ou combinatoire) : une méthode utilisant l'énorme puissance de calcul des ordinateurs consiste à regarder tous les cas possibles. Cela n'est pour autant possible que dans certains cas particuliers (la combinatoire est souvent plus forte que l'énorme puissance des ordinateurs, aussi énorme soit-elle) ;
- décomposition top-down / bottom-up : (décomposition descendante, décomposition remontante) les décompositions top-down consistent à essayer de décomposer le problème en sous-problèmes à résoudre successivement, la décomposition allant jusqu'à des problèmes triviaux faciles à résoudre. L'algorithme global est alors donné par la composée des algorithmes définis au cours de la décomposition. La démarche bottom-up est la démarche inverse, elle consiste à partir d'algorithmes simples, ne résolvant qu'une étape du problème, pour essayer de les composer pour obtenir un algorithme global ;
- pré-traitement / post-traitement : parfois, certains algorithmes comportent une ou deux phases identifiées comme des pré-traitements (à faire avant l'algorithme principal), ou post-traitement (à faire après l'algorithme principal), pour simplifier l'écriture de l'algorithme général ;
- programmation dynamique : elle s'applique lorsque le problème d'optimisation est composé de plusieurs sous-problèmes de même nature, et qu'une solution optimale du problème global s'obtient à partir de solutions optimales des sous-problèmes.
Les heuristiques
[modifier | modifier le code]Pour certains problèmes, les algorithmes ont une complexité beaucoup trop grande pour obtenir un résultat en temps raisonnable, même si l’on pouvait utiliser une puissance de calcul phénoménale. On est donc amené à rechercher la solution de façon non systématique (algorithme de Las Vegas) ou de se contenter d'une solution la plus proche possible d’une solution optimale en procédant par essais successifs (algorithme de Monte-Carlo). Puisque toutes les combinaisons ne peuvent être essayées, certains choix stratégiques doivent être faits. Ces choix, généralement très dépendants du problème traité, constituent ce qu’on appelle une heuristique. Le but d’une heuristique n'est donc pas d'essayer toutes les combinaisons possibles, mais de trouver une solution en un temps raisonnable et par un autre moyen, par exemple en procédant à des tirages aléatoires. La solution peut être exacte (Las Vegas) ou approchée (Monte-Carlo). Les algorithmes d'Atlantic City quant à eux donnent de façon probablement efficace une réponse probablement juste (disons avec une chance sur cent millions de se tromper) à la question posée.
C’est ainsi que les programmes de jeu d’échecs ou de jeu de go (pour ne citer que ceux-là) font appel de manière très fréquente à des heuristiques qui modélisent l’expérience d’un joueur. Certains logiciels antivirus se basent également sur des heuristiques pour reconnaître des virus informatiques non répertoriés dans leur base, en s’appuyant sur des ressemblances avec des virus connus, c'est un exemple d'algorithme d'Atlantic City. De même le problème SAT qui est l'archétype du problème NP-complet donc très difficile est résolu de façon pratique et efficace par la mise au point d'heuristiques[11].
Exemples d’algorithmes, de problèmes, d'applications ou domaines d'application
[modifier | modifier le code]Il existe un certain nombre d’algorithmes classiques, utilisés pour résoudre des problèmes ou plus simplement pour illustrer des méthodes de programmation. On se référera aux articles suivants pour de plus amples détails (voir aussi liste des algorithmes) :
- algorithmes ou problèmes classiques (du plus simple ou plus complexe) :
- échange, ou comment échanger les valeurs de deux variables : problème classique illustrant la notion de variable informatique (voir aussi Structure de données),
- algorithmes de recherche, ou comment retrouver une information dans un ensemble structuré ou non (par exemple Recherche dichotomique),
- algorithme de tri, ou comment trier un ensemble de nombres le plus rapidement possible ou en utilisant le moins de ressources possible,
- problème du voyageur de commerce, problème du sac à dos, problème SAT et autres algorithmes ou approximations de solutions pour les problèmes combinatoires difficiles (dit NP-complets) ;
- algorithmes ou problèmes illustrant la programmation récursive (voir aussi algorithme récursif) :
- tours de Hanoï,
- huit dames, placer huit dames sur un échiquier sans qu’elles puissent se prendre entre elles,
- suite de Conway,
- algorithme de dessins récursifs (fractale) pour le Tapis de Sierpiński, la Courbe du dragon, le Flocon de Koch… ;
- algorithmes dans le domaine des mathématiques :
- calcul de la factorielle d'un nombre, de la Fonction d'Ackermann ou de la suite de Fibonacci,
- algorithme du simplexe, qui minimise une fonction linéaire de variables réelles soumises à des contraintes linéaires,
- fraction continue d'un nombre quadratique, permettant d'extraire une racine carrée, cas particulier de la méthode de Newton,
- dans le domaine de l'algèbre : l'algorithme d'unification, le calcul d'une base de Gröbner d'un idéal de polynôme et plus généralement presque toutes les méthodes de calcul symbolique,
- en théorie des graphes qui donne lieu à de nombreux algorithmes,
- test de primalité ;
- algorithmes pour et dans le domaine de l'informatique :
- cryptologie et compression de données,
- informatique musicale,
- algorithme génétique en informatique décisionnelle,
- analyse et compilation des langages formels (voir Compilateur et Interprète (informatique)),
- allocation de mémoire (ramasse-miettes).
Annexes
[modifier | modifier le code]Notes et références
[modifier | modifier le code]- Phillipe Collard et Philippe Flajolet, « Algorithmique », sur Encyclopædia universalis (consulté le ).
- Albert Dauzat, Jean Dubois, Henri Mitterand, Nouveau dictionnaire étymologique et historique, 1971
- Hoéné de Wronski, Introduction à la philosophie des mathématiques et technie de l'algorithmie, Chez Courcier, imprimeur-libraire pour les mathématiques, (lire en ligne)
- Par exemple, l'UQAM propose un cours intitulé « Algorithmie de base et interactivité », et l'université de Montréal, un cours intitulé « Algorithmie et effets audionumériques ».
- Donald Knuth, « Ancient Babylonian Algorithms », Communications of the ACM, vol. 15, no 7, , repris dans Donald Knuth, Selected Papers on Computer Science, Addison-Wesley, , p. 185, traduit en français sous le titre Algoritmes babyloniens anciens dans Donald Knuth (trad. P. Cégielski), Éléments pour une histoire de l'informatique, Librairie Eyrolles, .
- Christine Proust, « Mathématiques en Mésopotamie », Images des Mathématiques, (lire en ligne).
- Le calcul de π « est caractéristique des problèmes généraux rencontrés en algorithmique. » Phillipe Collard et Phillipe Flajolet, « Algorithmique : 1. L'exemple du calcul de π », sur Encyclopædia universalis (consulté le ).
- Stephen Wolfram (en) « Untangling the Tale of Ada Lovelace », sur blog.stephenwolfram.com
- En cryptographie, le terme codage est utilisé dans un sens différent.
- Hertel & Delattre V (2019) [SEAActu17h-20190302 Les algorithmes sont partout, leurs biais de conception nous trompent] ; le 02.03.2019
- (en) Moshe Vardi, Boolean Satisfiability: Theory and Engineering (Communications of the ACM, Vol. 57 Nos. 3, p. 5).
Bibliographie
[modifier | modifier le code]- (en) Donald E. Knuth, The Art of Computer Programming, vol. 2 : Seminumerical algorithms, Reading, Mass, Addison-Wesley Pub. Co, , 764 p. (ISBN 978-0-201-89684-8 et 978-0-321-75104-1, OCLC 781024586)
- Michel Quercia, Algorithmique : Cours complet, exercices et problèmes résolus, travaux pratiques, Vuibert, , 303 p. (ISBN 2-7117-7091-5)
- Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest et Clifford Stein (trad. de l'anglais), Algorithmique : Cours avec 957 exercices et 158 problèmes, Dunod, [détail de l’édition]
- Patrick Bosc, Marc Guyomard et Laurent Miclet, Conception d'algorithmes : principes et 150 exercices corrigés, Paris, Eyrolles, , 832 p. (ISBN 978-2-212-67728-7, BNF 45663637)
Articles connexes
[modifier | modifier le code]- Algorithme récursif
- Algorithme réparti
- Algorithme émergent
- Algorithme adaptatif
- Algorithme d'approximation
- Art algorithmique
- Liste d'algorithmes
- Métaheuristique
- Recherche opérationnelle
- Paradigme (programmation)
Liens externes
[modifier | modifier le code]- Qu’est-ce qu'un algorithme ? par Philippe Flajolet et Étienne Parizot sur la revue en ligne Interstices
- Notice dans un dictionnaire ou une encyclopédie généraliste :